Subsections
4 ハッシュマップ
4.1 基本的な考え方
単語のスペルから直に配列の添え字の値が導くことが出来れば,- スペルが同じで意味の異なる単語は無いものとする.
- スペルは最大,アルファベットで9文字とする.
- アルファベットに対して,整数を割り当てる.aが1,bが2,
cが3,
 ,zが26のようにである.もうひとつアルファ
ベット長い場合(空白)が必要で,それは0を割り当てる.このようにすれば,
英単語は整数
,zが26のようにである.もうひとつアルファ
ベット長い場合(空白)が必要で,それは0を割り当てる.このようにすれば,
英単語は整数
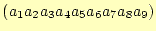 で表現できる.
で表現できる.
apple (1,16,16,12,5,0,0,0,0)
pineapple
(16,9,14,5,1,16,16,12,5)
(1,16,16,12,5,0,0,0,0)
pineapple
(16,9,14,5,1,16,16,12,5)
- これを9次元配列に格納することもできるが,少し工夫して1次元配列a[i]に格納する
ことを考える.つぎの演算により,添え字iを求めれば1次元配列とすることができ
る.
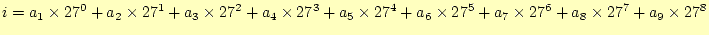
このようにスペルから直接添え字の値が計算できる配列に英単語を格納すると,とても高
速に探索,削除,追加ができるデータ構造となる.すべて,計算量のオーダーは![]() で
ある.しかし,この方法をよく考えると大きな問題がある.巨大なメモリー空間が必要な
のである.配列の最大の添え字は,
で
ある.しかし,この方法をよく考えると大きな問題がある.巨大なメモリー空間が必要な
のである.配列の最大の添え字は,
![]() となりとても現在のコンピューター
で取り扱うことができない.
となりとても現在のコンピューター
で取り扱うことができない.
このような配列に単語を格納すると,ほとんどその中は空になる.単語の数はそれほど多 くない.諸君の英和辞典の単語数を調べてもよく分かる.そこで,この配列の添え字を 0〜99999に圧縮することを考える.新たな添え字をjとすると,
j=i%100000;とすれば良い.100000で割った余りとすれば,0〜99999の値が得られる. このようにして,データにアクセスする方法をハッシュ法と言う.得られた値(0〜 99999)をハッシュ値と言い,キーを変数として,それを求める関数をハッシュ関数 と言う.
このようにすると,明らかに以下の問題点がある.
- 異なるキーで同じハッシュ値となる場合がある.
4.2 ハッシュ値の決め方
ハッシュを使う場合,配列にそのままデータを入れないで,データを表すポインターを入 れる方が便利である.ポインターが表すものを構造体とすれば,かなり柔軟に対応できる. 後で述べるがハッシュ値の重複(衝突)対策でリストやツリー構造を使う場合も対応が容易 である.ハッシュ法を使うためには,教科書に書いてあるとおり,以下のような動作が必要である.
- ハッシュ表を用意する.これは,ポインターを格納する配列である.
- ハッシュ関数(ハッシュ値)を決める.
ハッシュ表は,データを示すポインターを入れる配列である.キーを決めるとハッシュ関 数を計算してハッシュ値が決まる.このハッシュ値がこの配列の添え字の値となる.そし て,そこに格納されている配列の値(ポインター)により,データにアクセスする.
ハッシュ表を作るときにはデータ数よりも大きいことが望ましい.そうしないと,異なっ たキーでも同じハッシュ値となり,衝突が発生し,データの探索スピードが落ちてしまう. 衝突の問題は後で述べるので,ここではハッシュ関数の作り方を説明する.ハッシュ表の 大きさは素数とすることが望ましい.こうすることにより,キーのどのビットが変化して もハッシュ値の値を変化させることができる.
ハッシュ関数は,一般に,次の2つの手順により成り立っている.
- キーからなにがしかの演算を行い整数値を導き出す.
- 導き出された整数をなにがしかの演算により,ハッシュ表(配列)の大きさの整数に直 す.
4.3 ハッシュ値の重複対策
異なるキーであっても,同じハッシュ値となることがある.これが多いとハッシュ法の効 果が薄いのであるが,どうしても避けることができない.プログラマーはその対策を講じ なくてはならない.教科書に書かれている方法は,次の通りである.- リストを用いる方法(教科書 p.222 Fig.7-7)
- 2分木を用いる方法(教科書 p.224 Fig.7-9)
- 再ハッシュ(教科書 p.222 Fig.7-8 p.224 Fig.7-10)
ホームページ: Yamamoto's laboratory
著者: 山本昌志 Yamamoto Masashi
2006-01-30